Elasticsearch: tổ chức dữ liệu

Trong bài viết trước tôi đã trình bày những điều rất cơ bản khi biết đến Elasticsearch. Quả thật Elasticsearch đã đáp ứng rất tốt bài toán cụ thể của tôi. Thế nhưng, điều gì đã giúp Elasticsearch có thể làm được điều đó?
Tiếp tục tìm hiểu về Elasticsearch mới thấy, đằng sau những query và response tưởng như rất đơn giản kia là cả một tổ hợp rất phức tạp của biết bao tinh hoa công nghệ trên thế giới.
Trong bài viết này, tôi sẽ tiếp tục trình bày cách thức Elasticsearch tổ chức lưu trữ cũng như tìm kiếm dữ liệu. Đó chính là một phần rất quan trọng làm nên năng lực vượt trội của Elasticsearch.
Elasticsearch tổ chức dữ liệu như thế nào
Tài liệu và index
Elasticsearch sử dụng “index” để lưu trữ và xử lý dữ liệu, nó tương tự một cơ sở dữ liệu thông thường. Dữ liệu sẽ được lưu trữ thành các “tài liệu” dưới dạng JSON. Mỗi một index có nhiều “type” (tương tự như bảng trong cơ sở dữ liệu), điều này sẽ giúp chúng ta phân tách các loại dữ liệu khác nhau khi lưu vào cùng một index.
Mọi tài liệu được lưu vào trong cùng một type của một index sẽ có cấu trúc các trường và kiểu dữ liệu giống hệt nhau (giống như mỗi bảng có một schema trong các hệ cơ sở dữ liệu quan hệ)
Mỗi một index của Elasticsearch có một hoặc nhiều shard (tuỳ cấu hình, mặc định là 5). Các shard này lại tồn tại trên các node khác nhau. Nội dung về shard và node này liên quan nhiều đến kiến trúc của Elasticsearch (sẽ tìm hiểu ở phần sau), cũng là một phần rất quan trọng giúp Elasticsearch có thể thực hiện công việc tìm kiếm một cách nhanh chóng.
Shard cũng có hai loại là primary và replica, mỗi một primary shard sẽ có một vài (có thể là không có) shard replica (mặc định là 1). Elasticsearch sẽ đảm bảo là primary shard và replica shard sẽ tồn tại trên các node khác nhau.
Một đặc điểm rất quan trọng, đó là số lượng primary shard cho một index không thể thay đổi được sau khi index đã được tạo. Do đó, trong thực tế, chúng ta sẽ phải cân nhắc rất nhiều yếu tố để quyết định xem cần bao nhiêu primary shard cho mỗi index. Trừ khi bạn muốn tạo lại index và thêm dữ liệu vào từ đầu.
Như đã nói trong bài viết trước, Elasticsearch hoạt động dựa trên Lucene của Apache. Vậy nó dựa trên như thế nào? Đây chính là lúc Lucene được sử dụng.
Một shard thực chất là một Lucene index, đó mới là nơi thực sự lưu trữ dữ liệu, và bản thân shard cũng là một search engine. Là một Lucene index, nên một shard lại được tạo nên từ nhiều segment và mỗi segment là một inverted index với đầy đủ chức năng.
Segment cho phép Lucene có thể thêm tài liệu vào index một cách dễ dàng mà không cần quá nhiều xử lý với index.
Với mỗi yêu cầu tìm kiếm, mọi segment trong một index sẽ được sử dụng, và mỗi segment như vậy sẽ hoạt động một cách khá độc lập (điều này khiến nó sử dụng CPU và bộ nhớ). Điều đó có nghĩa là, nếu có quá nhiều segments, performance của thao tác tìm kiếm sẽ bị giảm đi, nhưng nếu ít segment quá thì lại không tận dụng hết được khả năng của máy chủ.
Để xử lý vấn đề này, Lucene thực hiện một thao tác khá thông minh là “gộp” các segment nhỏ lại thành một segment lớn hơn. Tuy nhiên, điều này cũng có hai mặt: nếu thao tác gộp này được tiến hành không cẩn thận, Elasticsearch có thể rơi vào sai lầm là gộp tất cả segment vào làm một và bỏ phí rất nhiều tài nguyên (điều này cũng khiến performance giảm đi).
Node và cluster
Node là cơ sở trong kiến trúc server của Elasticsearch, và nhiều node hợp với nhau tạo thành cluster.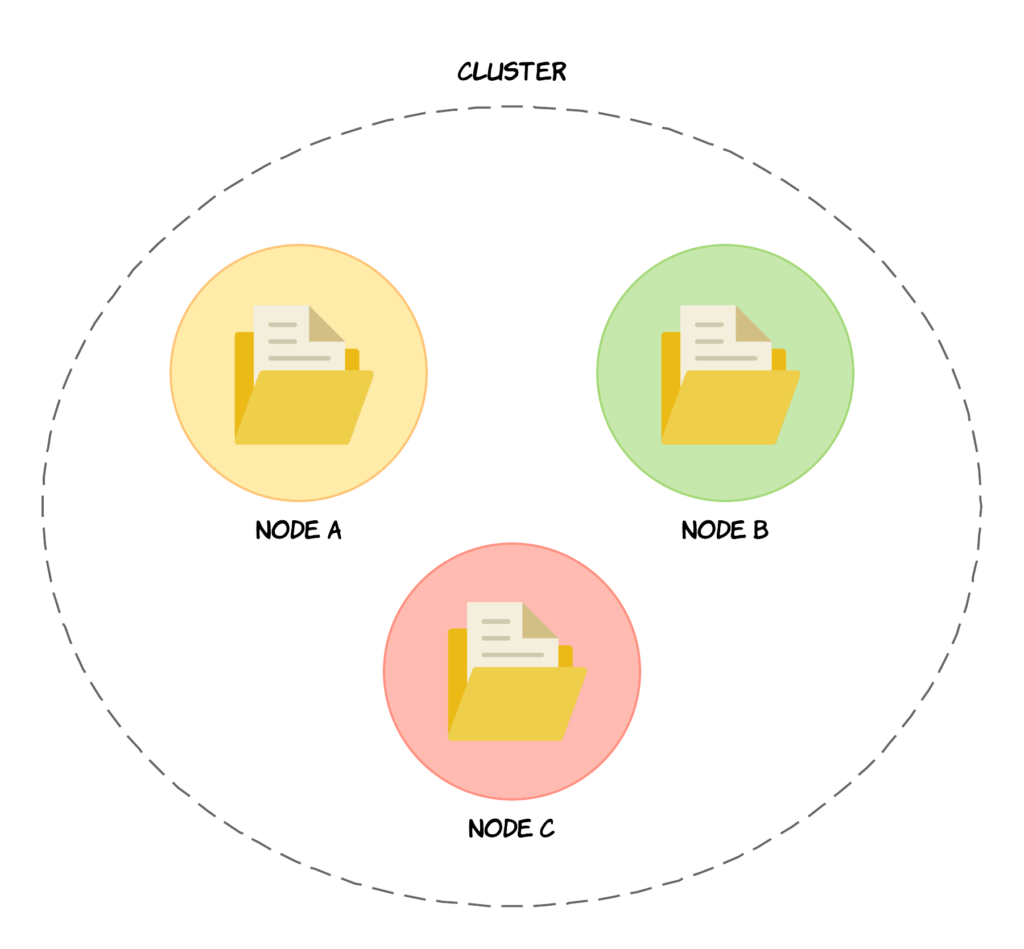
Một node là một server Elasticsearch, về logic là các node chạy độc lập với nhau, thực tế nó có thể chạy trên một (thường với môi trường phát triển hoặc test) hoặc nhiều server vật lý (thường với môi trường production). Tập hợp các node hoạt động cùng với nhau tạo thành một cluster, mỗi node trong cluster chứa một phần dữ liệu của cluster đó (và đương nhiên, toàn bộ dữ liệu của một cluster sẽ được chia ra cho các node).
Mỗi node sẽ tham gia vào quá trình index và tìm kiếm dữ liệu trong cluster. Tất nhiên là mỗi node chỉ chứ một phần dữ liệu của cluster và nó chỉ thực hiện tìm kiếm trên dữ liệu mà nó lưu trữ mà thôi. Như chúng ta đã biết, các truy vấn của người dùng đều thông qua HTTP request, và cluster sẽ chuyển những truy vấn đó cho các node của nó.
Mỗi node khi nhận được truy vấn sẽ có trách nhiệm thực hiện công việc với dữ liệu của nó. Một điểm khá hay đó là các node trong cùng một cluster hiểu được các node khác và do đó, nó có thể chuyển tiếp truy vấn của người dùng cho một node khác. Việc chuyển tiếp này hoàn toàn được thực hiện nội bộ bên trong cluster và với người dùng, thì hầu như trong suốt.
Node có 3 loại khác nhau: master, data và client. Một cluster sẽ tự động chọn ra một node làm master từ các node của nó. Node master sẽ có nhiệm vụ điều phối công việc của cluster, ví dụ như phân bố các shard, tạo/xoá các index, v.v… Chỉ có node master mới có khả năng cập nhật trạng thái của cluster.
Tất nhiên là toàn bộ việc này Elasticsearch sẽ tự động thực hiện cho chúng ta. Về cơ bản không biết những chuyện này cũng không ảnh hưởng gì đến công việc. Nhưng tất nhiên, là một developer thì biết vẫn tốt hơn.
Node data là node mà các shard được phân bố, có nhiệm vụ thực hiện các công việc như index tài liệu, tìm kiếm và thống kê. Node client hoạt động như một load balancer có nhiệm vụ định tuyến các truy vấn của người dùng như index hay tìm kiếm. Một cluster có thể không có node client.
Cluster và node được định danh bởi tên (duy nhất). Mặc định, tên của cluster sẽ là elasticsearch (tất cả đều viết thường), còn các node được gán tên là một UUID (Universally Unique Identifier). Nếu muốn thay đổi tên định danh này thì chúng ta cũng có thể làm được. Chỉ có một điều cần lưu ý, đó là tên của node rất quan trọng, vì nó còn liên quan đến việc xác định server vật lý (hoặc server ảo) tương ứng với node đó.
Từ bài toán thực tế, tôi nghĩ rằng chúng ta nên thay đổi tên mặc định của cluster, và chỉ của cluster mà thôi. Vì đơn giản, nếu cứ theo mặc định, node sẽ được thêm và cluster elasticsearch. Có nghĩa là, khi chúng ta khởi tạo node mới, mọi node đó sẽ được thêm vào cluster mặc định.
Thực tế thì việc này rất không tốt, có khả năng node sẽ được thêm vào cluster ngoài ý muốn nếu developer sử dụng nhiều kiểu môi trường khác nhau trong quá trình phát triển. Việc này cũng ít gây ra vấn đề quá lớn, nhưng nếu gặp bug thì quá trình tìm hiểu, điều tra có thể sẽ rất phức tạp, trong khi chúng ta chỉ cần bỏ thêm một chút công sức là có thể phòng tránh được.
Tổng hợp lại, kiến trúc của Elasticsearch có thể hình dung như hình ảnh dưới đây:
Một cluster, về mặt kỹ thuật là có bao nhiêu node cũng được, thậm chí chỉ có 1 node cũng không sao. Kiến trúc này của Elasticsearch giúp nó có khả năng mở rộng cực kỳ dễ dàng. Cụ thể, Elasticsearch cho phép chúng ta mở rộng theo chiều ngang một cách nhanh chóng mà không hề cần một sự thay đổi nào trong code.
Thử so sánh với một hệ quản trị cơ sở dữ liệu như MySQL chẳng hạn, liệu chúng ta có thể dễ dàng chuyển từ 1 server thành 2 server mà không cần thay đổi code hay không?
Lưu trữ dữ liệu và tìm kiếm
Storage Model
Elasticsearch sử dụng Lucene của Apache – một thư viện full text search viết bằng Java. Về bản chất, nó sử dụng một cấu trúc dữ liệu gọi là inverted index (chỉ mục đảo ngược) để có thể thực hiện tìm kiếm với hiệu suất cao.
Tài liệu chính đơn vị cơ sở để quản lý dữ liệu trong Elasticsearch và inverted index được tạo ra bằng việc tokenize (thuật ngữ trong Elasticsearch) các khái niệm trong tài liệu. Bằng việc sử dụng kỹ thuật inverted index, một bảng chỉ mục các khái niệm và danh sách tài liệu liên quan đến khái niệm đó sẽ được tạo ra.
Nó khá tương đồng với chỉ mục của một cuốn sách, nơi hiển thị một danh sách các khái niệm được sử dụng cùng với số trang mà nó xuất hiện. Trong Elasticsearch, khi nói rằng một tài liệu được index, thì chúng ta hiểu rằng, inverted index của tài liệu đó đã được tạo ra.
Ví dụ, khi chúng ta cần tìm từ khoá “Việt Nam”, Elasticsearch sẽ thực hiện tìm kiếm trên inverted index (rất nhanh do các từ được sắp xếp), tìm được từ khoá “Việt Nam”, sau đó trả về ID của các tài liệu tương ứng. Để có thể tìm kiếm nâng cao hơn (ví dụ, tìm với từ khoá “Viet Nam”), thì quá trình phân tích và index tài liệu là rất quan trọng.
Ngoài ra, quá trình tìm kiếm thực tế còn phức tạp hơn nữa, khi mà Elasticsearch còn phải đánh giá mức độ tương qua giữa những từ trong index với từ khoá cần tìm.
Tìm kiếm
Quá trình tìm kiếm tài liệu sẽ diễn ra theo 2 giai đoạn:
Giai đoạn query
Đầu tiên, truy vấn tìm kiếm sẽ đến node điều phối, ở đây, truy vấn này sẽ được chuyển tiếp đến mọi shard (cả primary và replica) trong index. Mỗi shard sẽ thực hiện thao tác tìm kiếm tương ứng với truy vấn một cách độc lập và trả về ID của các tài liệu có độ tương quan cao nhất (mặc định sẽ là 10 tài liệu có điểm tương quan cao nhất được trả về).
Các ID này được trả về cho node điều phối, ở đây, nó sẽ được gộp với kết quả của các shard khác và sắp xếp lại để tìm ra những tài liệu có độ tương quan cao nhất.
Gia đoạn fetch
Sau khi node điều phối gộp và sắp xếp lại kết quả nhận được từ các shard, nó sẽ thực hiện thao tác lấy thông tin của tài liệu đó. Các shard lại thực hiện công việc của mình và trả về tài liệu (toàn bộ tài liệu chứ không chỉ ID như giai đoạn trước) cho node điều phối.
Sau khi quá trình lấy dữ liệu đã xong, kết quả sẽ được trả về cho client.
Lưu ý rằng, để thực hiện tìm kiếm hiệu quả, mọi node trong cluster cần biết được trạng thái của cluster đó. Trạng thái của cluster sẽ bao gồm các thông tin như mỗi node có chứa index và shard nào. Nhờ đó, mọi node đều có thể trở thành node điều phối (và Elasticsearch sẽ thay đổi node điều phối trong trường hợp node được chọn không hoạt động).
Độ tương quan
Độ tương quan được đánh giá bởi điểm mà Elasticsearch chấm cho từng tài liệu khi thực hiện thao tác tìm kiếm. Mặc định, thuật toán để đánh giá độ tương quan được sử dụng là thuật toán tf/idf (term frequency/inverse document frequency). Điểm tương quan cuối cùng chính là tổ hợp của điểm td-idf với một vài yếu tố đánh giá khác, như mức độ khớp của tài liệu với từ khoá.
# Tìm kiếm trên nhiều trường với các mức độ khác nhau
"query": {
"function_score": {
"query": {
"multi_match": {
"query": "Lambda Expressions",
"fields": [
"title",
"tags^0.8",
"speakers.name^0.6",
"description^0.3"
]
}
},
"functions": [
{
# Nội dung kỹ sẽ có độ quan trọng thấp hơn
# dựa trên khoảng cách Gauss
"gauss": {
"publishedOn": {
"scale": "130w",
"offset": "26w",
"decay": 0.3
}
}
}
]
}
}
Đánh giá hiệu năng tìm kiếm
Dựa trên quy trình thực hiện truy vấn tìm kiếm, chúng ta có thể dựa vào những thông số như sau để đánh giá hiệu năng của việc tìm kiếm, đồng thời cũng từ đó mà biết vấn đề nằm ở đâu (trong trường hợp việc tìm kiếm diễn ra lâu):
# Số truy vấn đang thực hiện
indices.search.query_current
# Độ trễ của truy vấn
avg = indices.search.query_time_in_millis / indices.search.query_total
# Độ trễ khi fetch
# Nếu đỗ trễ cao, nguyên nhân có thể do ổ cứng
# hoặc có quá nhiều truy vấn
avg = indices.search.fetch_time_in_millis / indices.search.fetch_total
Indexing
Tuỳ biến mapping
Các trường có kiểu dữ liệu là string thì thường sẽ chứa text (và tìm kiếm thường là full text search). Vì vậy, để tìm kiếm hiệu quả, giá trị của những trường này cần được phân tích trước khi index. Khi tìm kiếm theo kiểu full text search thì từ khoá cũng sẽ được phân tích trước khi tiền hành tìm kiếm.
Vì vậy, với các trường string, hai giá trị cực kỳ quan trọng để có thể tìm kiếm chính xác là index và analyzer.
Với index, có 3 lựa chọn cho chúng ta:
analyzed: phân tích text rồi sau đó index nó (dùng cho full text search).not_analyzed: index trường với toàn bộ giá trị của nó mà không phân tích gì (không thể full text search).no: không index, trường này sẽ không dùng để tìm kiếm.
Để phân tích một trường string, thì analyzer là rất quan trọng để làm điều này. Chúng ta cần cấu hình analyzer cho từng trường, và bộ phân tích này sẽ được sử dụng cho cả quá trình phân tích để index và phân tích từ khoá để tìm kiếm.
Mặc định, Elasticsearch sử dụng standard analyzer, tuy nhiên bộ phân tích này thường kém hiệu quả với các ngôn ngữ không phải tiếng Anh. Ngoài standard analyzer, Elasticsearch còn tích hợp sẵn nhiều bộ phân tích khác nữa, như whitespace, simple và english. Tuy nhiên, chúng thường chỉ có tác dụng với tiếng Anh mà thôi.
Với các ngôn ngữ khác, chúng ta cần sử dụng thêm plugin để có thể dùng các analyzer khác cho hiệu quả hơn trong quá trình tìm kiếm:
{
"name": {
"type": "string",
"analyzer": "name_analyzer"
},
"name_analyzer": {
"type": "custom",
"char_filter": ["icu_normalizer"],
"tokenizer": "name_tokenizer",
"filter": ["kana_filter"]
},
"name_tokenizer": {
"type": "nGram",
"min_gram": 1,
"max_gram": 1,
"token_chars": ["letter", "digit", "punctuation", "symbol"]
}
}
Index Refresh
Khi có một truy vấn yêu cầu index một tài liệu, nội dung đó sẽ được thêm vào translog và được lưu tạo vào buffer trên bộ nhớ trong. Khi tiến hành index refresh (mặc định mỗi giây một lần), tiến trình refresh sẽ tạo segment ngay trên bộ nhớ trong từ buffer trước đó. Tới lúc này, tài liệu cần index đã có thể tìm kiếm được.
Sau đó, buffer trên bộ nhớ trong sẽ bị xoá đi. Dần dần quá trình này sẽ tạo ra một tập các segment, rồi các segment lại được gộp lại với nhau thành segment lớn hơn để đảm bảo việc sử dụng các tài nguyên của máy chủ (CPU, bộ nhớ, v.v…) được tối ưu.
Quá trình index refresh là một hoạt động rất tốn kém, do đó nó thường được đặt lịch chạy định kỳ chứ không phải được kích hoạt ngay sau khi index.
Nếu chúng ta cần index một lượng lớn tài liệu và không có nhu cầu gấp trong việc tìm kiếm ngay các tài liệu đó, chúng ta có thể tìm cách tối ưu hiệu năng của quá trình index bằng cách kéo giãn khoảng thời gian mà index refresh được thực hiện.
Index Flush
Các segment được ghi trên bộ nhớ trong qua index refresh như ở trên thực ra không an toàn (do ghi trên bộ nhớ trong nên nó không được đảm bảo sẽ được duy trì tốt). Nếu như node xảy ra lỗi nào đó, các segment này sẽ mất hết thông tin.
Vì có translog nên chúng ta vẫn có thể khôi phục lại thông tin được. Log được ghi vào đĩa cứng 5 giây một lần (mặc định), hoặc sau khi các thao tác như index, xoá, cập nhật thành công.
Tuy nhiên, sử dụng translog để khôi phục lại cũng gặp nhiều hạn chế, bởi translog cũng bị giới hạn dung lượng. Do đó, cứ mỗi 30 phút, hoặc khi translog vượt quá giới hạn về dung lượng (mặc định là 512MB), một quá trình gọi là flush sẽ được thực thi.
Trong quá trình flush, mọi tài liệu được lưu ở buffer trên bộ nhớ trong sẽ được index và lưu vào các segment, và các segment đang ở trên bộ nhớ trong sẽ được ghi vào ổ cứng, đồng thời translog sẽ bị xoá.
Dưới đây là các cấu hình của Elasticsearch liên quan đến index flush:
# Đỗ trễ của index
# Giá trị càng cao, số tài liệu cần index càng nhiều
avg = index_time_in_millis/ index_total
# Giới hạn kích thước của translog, nếu vượt quá sẽ flush
# Tăng giá trị này lên, chúng ta có thể tăng throughput của index
index.translog.flush_threshold_size
# Sau bao nhiêu thao tác thành công sẽ flush
# Mặc định là không giới hạn
index.translog.flush_threshold_ops
# Thời gian chạy flush định kỳ, mặc định là 30 phút
index.translog.flush_threshold_period
# Thiết lập độ thường xuyên của việc kiểm tra flush cần hay không
# Mặc định là 5s, sẽ chọn giá trị ngẫu nhiên trong khoảng 5-10 giây
index.translog.interval
Một số vấn đề hay gặp với Elasticsearch
Cluster health
Đây là một vấn đề rất quan trọng nhưng nhiều khi không được quan tâm đúng mức. Với các cluster, chúng ta có thể kiểm tra trạng thái hoạt động của nó (gọi là cluster health) bằng cách:
GET _cluster/health?pretty
{
"task_max_waiting_in_queue_millis" : 0,
"number_of_pending_tasks" : 0,
"number_of_data_nodes" : 1,
"unassigned_shards" : 190,
"status" : "yellow",
"cluster_name" : "elasticsearch",
"active_shards" : 193,
"initializing_shards" : 0,
"timed_out" : false,
"delayed_unassigned_shards" : 0,
"active_shards_percent_as_number" : 50.3916449086162,
"active_primary_shards" : 193,
"number_of_in_flight_fetch" : 0,
"relocating_shards" : 0,
"number_of_nodes" : 1
}
Kết quả trả về ở trên, chúng ta có thể dựa vào status để biết tình trạng hiện tại của cluster. Nó có thể là một trong 3 giá trị:
green: Tất cả hoạt động bình thường.yellow: Tất cả primary shard đã hoạt động, vẫn còn replica shard chưa hoạt động.red: Có primary shard chưa hoạt động.
Đây là thông số rất quan trọng, liên quan trực tiếp nên hiệu năng của Elasticsearch. Trạng thái red thường khó gặp trong thực tế, nhưng yellow thì rất nhiều.
Tại sao lại có replica shard chưa hoạt động?
Tìm hiểu một thời gian thì tôi cũng hiểu ra, mặc định của Elasticsearch là mỗi index sẽ có 5 primary shard, và mỗi primary shard lại có 1 relica shard. Và Elasticsearch sẽ sắp xếp sao cho primary và replica shard không nằm trên cùng một node.
Vấn đề là, chúng ta thường (nhất là trong môi trường phát triển) chỉ sử dụng Elasticsearch với 1 node duy nhất. Do đó, node chỉ có thể chứa primary shard, còn replica shard thì không biết đặt ở đâu.
Cách giải quyết thì rất đơn giản, thêm node cho Elasticsearch là xong. Lưu ý rằng, việc thêm node nhưng node này lại nằm trên các server vật lý khác nhau thì cần thêm một chút cầu hình nữa.
Quá nhiều tài liệu
Việc tìm kiếm của Elasticsearch được phân trang, thông qua hai giá trị from và size. Việc phân trang này diễn ra rất phổ biến, trên hầu hết các ứng dụng và thậm chí, trên giao diện, người dùng có thể dễ dàng nhảy từ trang này sang trang khác.
Nhưng, Elasticsearch có những vấn đề của riêng nó liên quan đến phân trang, khi mà người dùng nhảy đến những trang quá lớn, nhất là trang cuối cùng.
Với Elasticsearch, nó sẽ phải thực hiện tính toán, đánh giá độ tương quan cho từng trang. Ví dụ, bạn cần truy cập trang thứ 20, thì Elasticsearch sẽ phải tính toán và thực hiện tìm kiếm trên tất cả các trang từ 1-20. Trong trường hợp thì sẽ là thực hiện tính toán trên 20 * 20 * 5 = 2000 bản ghi (nếu phân trang là 20 bản ghi mỗi trang).
Số trang càng lớn, mức độ tính toán càng nhiều. Do đó, trên thực tế, chúng ta sẽ phải tìm cách giải quyết vấn đề này, dù tỉ lệ người dùng tìm đến các trang sâu như vậy là không nhiều.
Một trong số những cách có thể áp dụng đó là sử dụng scroll thay cho truy vấn search thông thường.
Welcome

Đây là thế giới của manhhomienbienthuy (naa). Chào mừng đến với thế giới của tôi!
Bài viết liên quan


Bài viết mới





Chuyên mục
Lưu trữ theo năm
Thông tin liên hệ
Cảm ơn bạn đã quan tâm blog của tôi. Nếu có bất điều gì muốn nói, bạn có thể liên hệ với tôi qua các mạng xã hội, tạo discussion hoặc report issue trên Github.